WordCount
Grep
NaiveBayes
PageRank
Kmeans
Top 100 big data systems, BAFST and ICT, CAS
The BigData100 is an open source project for benchmarking and ranking big data systems. The benchmarks we use are selected from BigDataBench . Currently, the big data systems include Hadoop, Spark, Flink, Hive on Hadoop, Impala, and the workloads cover offline batch processing, iterative machine learning, and interactive query processing from different domains. We will include more systems and workloads in near future.
The benchmarks come from BigDataBench . The batch processing and iterative machine learning part support Hadoop, Spark and Flink, while the interactive query processing benchmarks cover systems like Impala, Spark SQL, Hive on Hadoop, Hive on Tez and Hive on Spark. In the first part, there are 4 data sets and 6 workloads in BigData100. Table 1 summarizes the real-world data sets and scalable data generation tools included into BigData100; Table 2 presents the workloads of BigData100 for batch processing and machine learning.
| Data sets | Raw data size | Scalable data set |
| Wikipedia Entries | 1.600,000,000 English words (unstructured text) | Text Generator of BDGS of BigDataBench |
| Amazon Movie Reviews | 5,700,000 reviews (semi-structured text) | Text Generator of BDGS of BigDataBench |
| Google Web Graph | 16777216 nodes, 99184770 edges (unstructured graph) | Graph Generator of BDGS of BigDataBench |
| Facebook Social Network | 460,000,000 vectors | Graph Generator of BDGS of BigDataBench |
| TeraSort | IO-Intensive | Text | From Hadoop |
| WordCount | CPU-Intensive | Text | From BigDataBench |
| Grep | CPU-Intensive | Text | From BigDataBench |
| PageRank | Hybrid | Graph | From BigDataBench |
| K-means | CPU-Intensive | Graph | From BigDataBench |
| NaiveBayes | CPU-Intensive | Text | From BigDataBench |
Jingwei Li, BAFST, lijingwei@mail.bafst.com
Xinhui Tian, ICT, CAS, tianxinhui@ict.ac.cn
Jianfeng Zhan, ICT, CAS, zhanjianfeng@ict.ac.cn
Now we use a 16-node cluster as the testbed. Table 3 summarizes the configurations of systems.
| Computation nodes | 16 nodes |
| CPU per node | 2*Intel Xeon E5645 |
| Memory per node | 32GB |
| Disk per node | 1TB x 2 SATA disks |
| Network | Broadcom NetXtreme II Gigabit Ethernet |
We released some preliminary results of BigData100.
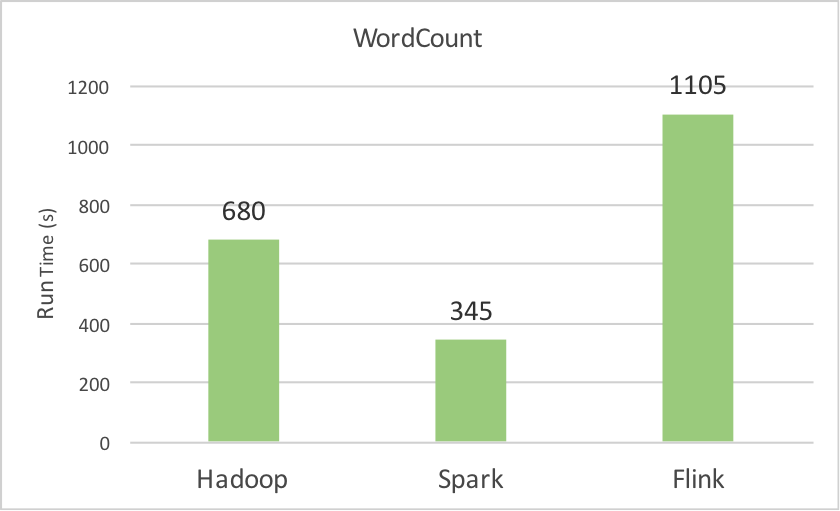
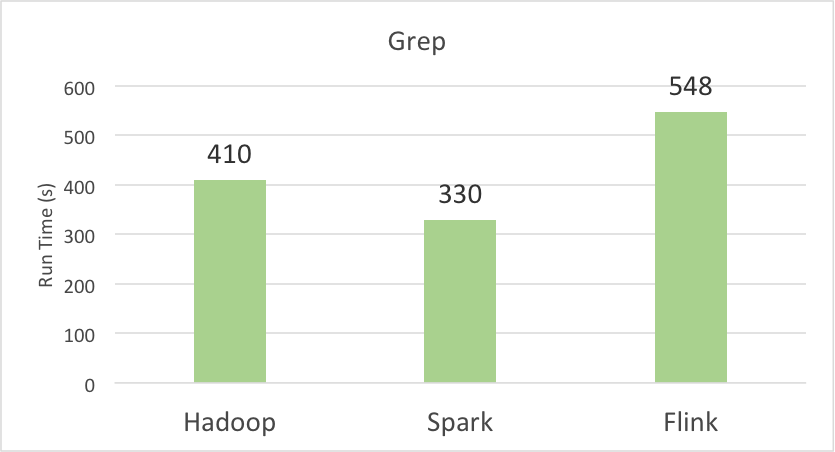
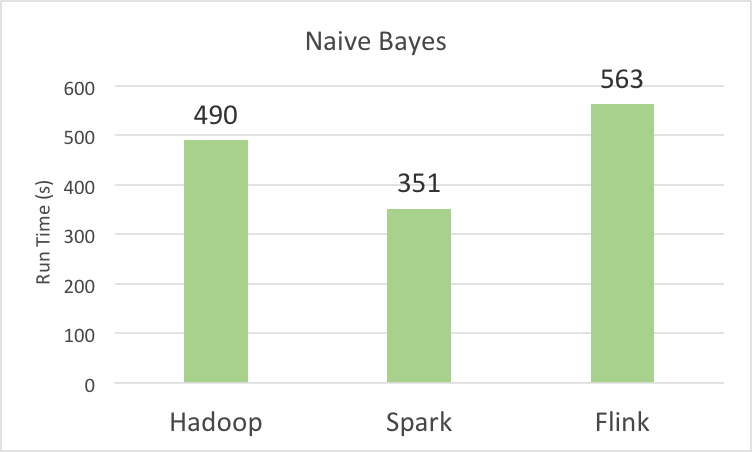
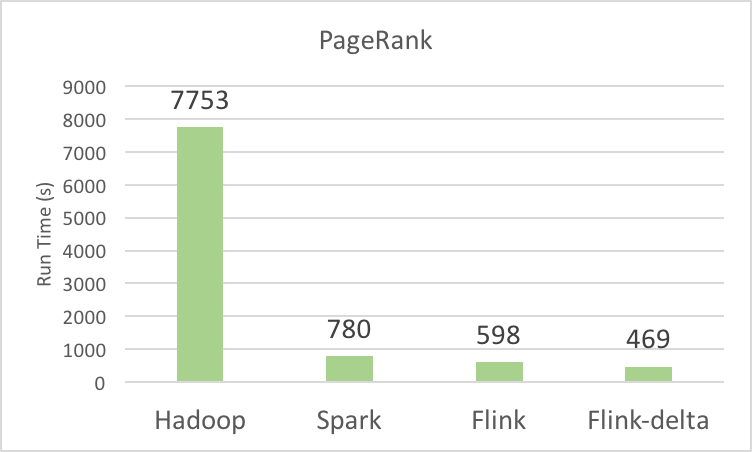
The first BigData100 ranking report covers Spark, Hadoop, and Flink. Table 4 shows the performance numbers of different systems running different benchmarks.
| Workload | Hadoop v. 2.7.1 | Spark v 1.5.1 | Flink 0.9.1 |
| WordCount | 680 | 1620 | 1105 |
| Grep | 672 | 1860 | 1676 |
| NaiveBayes | 490 | 780 | 563 |
| PageRank | 7753 | 780 | 598 (469 in delta PageRank) |
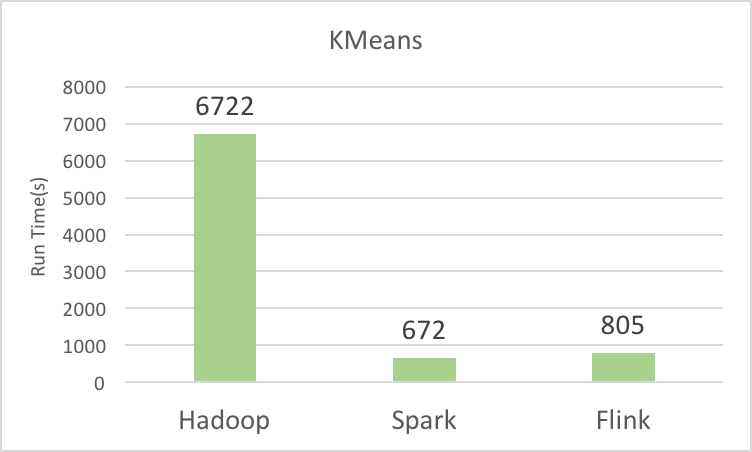
| Kmeans | 6722 | 672 | 805 |
In this part, we have tested five systems with three queries included in BigDataBench. The queries adopt a schema of e-commerce includeing three tables of items, customers, and orders. These three queries cover common operations such as select, aggregation, and join. The data size is described in Table 5, and the results are shown as below. Currently, we only consider the text format for these three tables.
| Itme | 2.19 GB |
| Customer | 14.14 GB |
| Order | 101.99 GB |
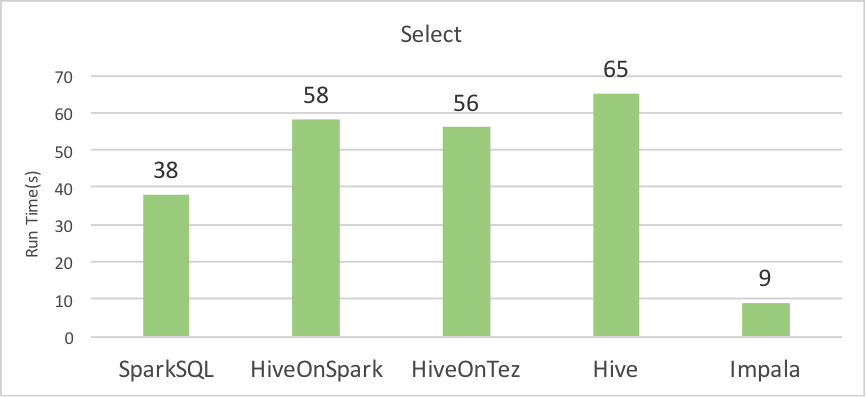
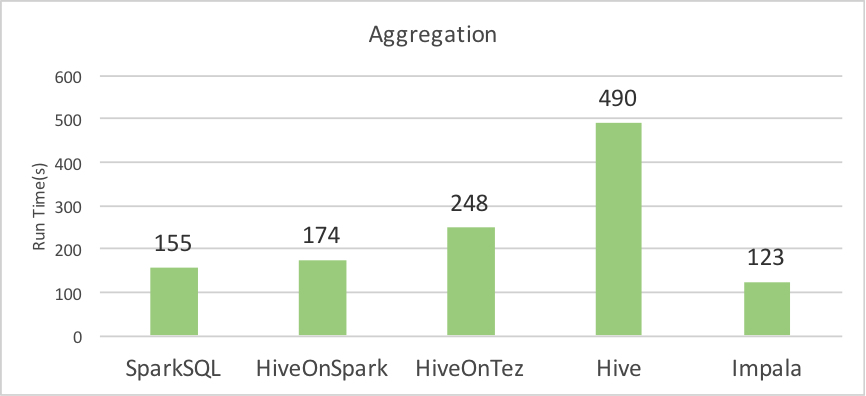
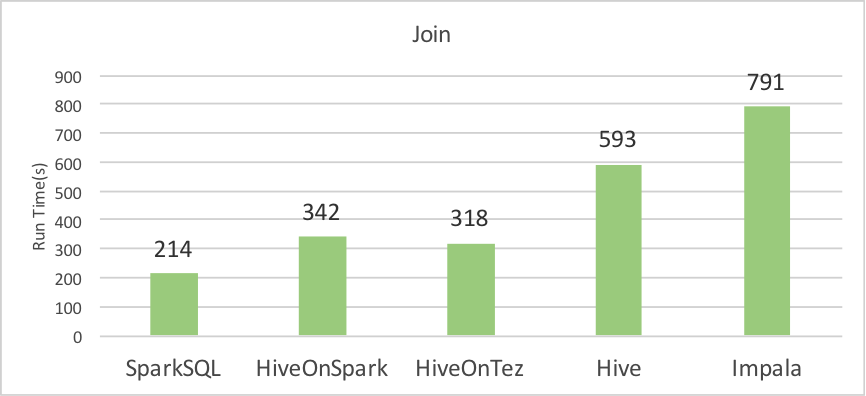
Table 6 presents the details of different big data run-time systems configurations
| Version | 2.7.1 |
| yarn.nodemanager.resource.cpu-vcores | 12 |
| yarn.scheduler.maximum-allocation-vcores | 12 |
| yarn.nodemanager.resource.memory-mb | 22528 |
| mapreduce.map.memory.mb | 1024 |
| mapreduce.reduce.memory.mb | 1024 |
| Version | 1.5.1 |
| SPARK_EXECUTOR_CORES | 12 |
| SPARK_EXECUTOR_MEMORY | 22G |
| Spark.storage.memoryFraction | 0.2 (0.5 for iteration) |
| Spark.shuffle.manager | Sort |
| Spark.default.parallelism | 600 |
| Version | 0.9.1 |
| Taskmanager.heap.mb | 22528 |
| Taskmanager.numberOfTaskSlots | 12 |
| Parallelism.default | 150 |
| Taskmanager.network.numberOfBuffers | 9000 |